Intro To Fuzzing
Fuzzing
Fuzzing is the generalized process of feeding random inputs to an executable program in order to create a crash. This crash reveals the presence of a software bug that allows a developer to patch it or could possibly be used as part of an exploit. It is one of the efficient ways in finding issues in a program or software. The random inputs are made of generators and vulnerability issues are based on debugging tools. Generators utilize a combination of static fuzzing vectors or totally random inputs. The Fuzzers are dependent on file-formats and data-types. One disadvantage of simple fuzzing is that it uses large binary files for every corner test case, which take years to execute.
Types of fuzzers:
- Dumb fuzzers
- Fuzzer - No idea of program path/input file format.
- User - No understanding of file format/network protocol is required.
- Can take lot of time (depending up on your luck).
- Random input
- No code coverage
- Example - radamsa
- Mutation and Generation fuzzers
- Fuzzer - No idea of program path but can generate input files based on given template.
- User - Needs understanding of input file or protocol.
- As long as a user knows about the correct input and can create valid templates.
- Example - Peach, Sulley
- Coverage guideded fuzzers
- Fuzzer - aware of program paths being taken and can change input based on that.
- User - No idea of program path or file format is required.
- User don’t need to do anything, fuzzer can handle input generation based on coverage data.
- Mutates file and check for new code path coverage/crash
- New Code path -> Add to Queue
- Crash -> Save the input
- Example - AFL, AFL++, Honggfuzz, libfuzzer
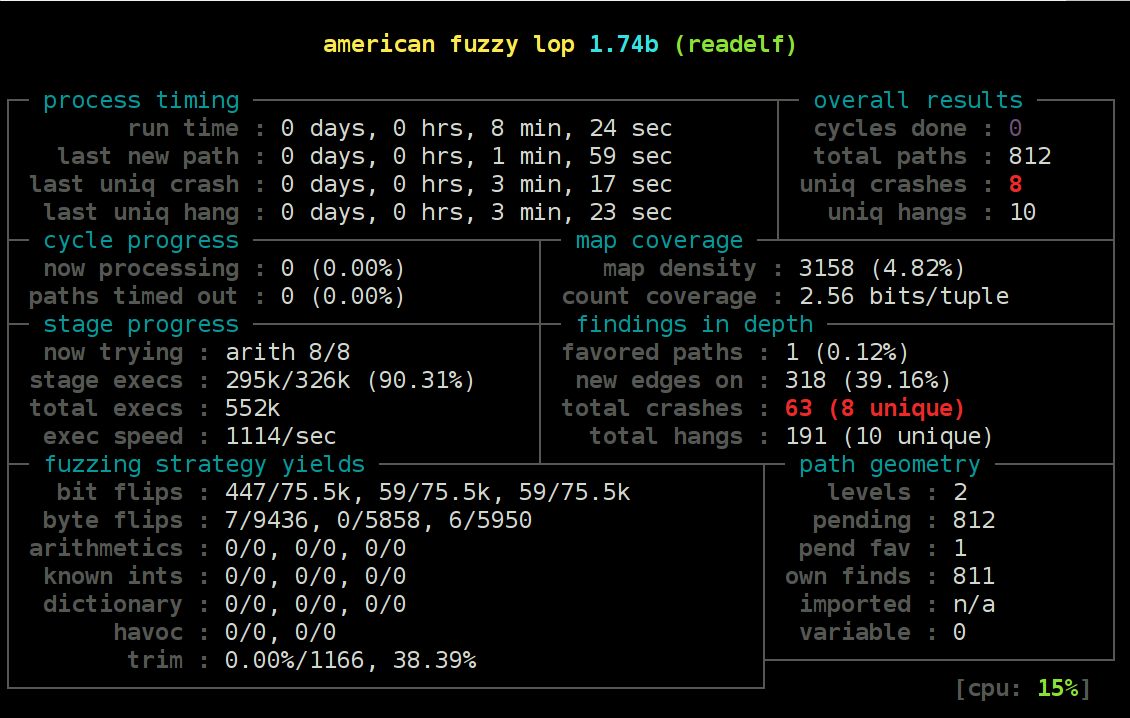
Feedback Driven Coverage
Also known as smart “fuzzing” is the concept of using a measurement such as increasing lines of code coverage, edge coverage, increasing buffer length or memory usage, as a heuristic to drive the direction of future random input choices. Instead of blindly trying every possible random input, the program detects that a previous choice of input has unlocked a new previously unseen section of program code and, then spends extra effort on this new code by maintaining the input choices that reached the new code static, and attempting randomized input that “exercises” new code beyond this point.The random input which created a new section of the program is recorded in a coverage map and helps the fuzzer to generate new random inputs based on the map. For example a line in the code isn’t traversed before and the inputs are aligned to mutate for executing the line of code.
The conceptual idea behind feedback driven coverage is that the more code that you “exercise”, the greater chance that you will succeed at creating a crash.
Corpus
A corpus is a collection of inputs that a fuzzer uses to test a program. These inputs can range from files, URLs, binary data, or any other data format that the target application expects to receive. The quality and diversity of this corpus directly impact the effectiveness of the fuzzing process. A well-constructed corpus can help a fuzzer explore more code paths, uncovering hidden vulnerabilities that would otherwise remain undetected.
The Significance of a Good Corpus
The strength of a good corpus lies in its ability to trigger new and interesting behaviors in the application being tested. Unlike random input generation, which might waste time on inputs that don’t contribute to code coverage or vulnerability discovery, a thoughtfully curated corpus can steer the fuzzer towards more fruitful testing paths. It serves as the initial seed data from which the fuzzer mutates and generates new test cases, making the initial set of inputs crucial for successful fuzzing campaigns.
Corpus Mimization
Why do we need to Minimize input corpus?
- Filter out the files which doesn’t result in new path.
- Filter out large files.
Tools like AFL’s afl-cmin can help minimize your corpus by removing inputs that don’t contribute additional code coverage, ensuring your fuzzer spends time on inputs that matter.
Creating a Good Corpus
Creating an effective corpus can sometimes be difficult but often times you can downlaod good corpuses off the internet.
- Good variety of corpus -> https://files.fuzzing-project.org/
- Multimedia file corpus -> https://samples.ffmpeg.org/
- Others -> Search github/google
A well-crafted corpus is a cornerstone of effective fuzzing. By focusing on diversity, edge cases, and real-world data, while minimizing redundancy, you can create a corpus that significantly enhances your fuzzing efforts. Remember, the goal of fuzzing is not just to find vulnerabilities but to explore the application’s behavior as comprehensively as possible.
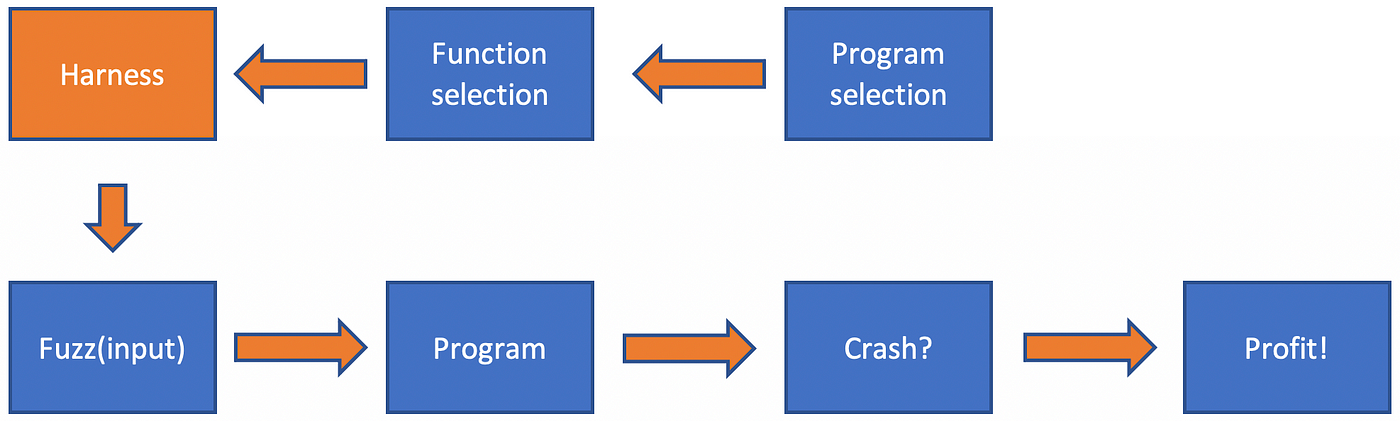
Harnessing
For simple executable programs, you simply provide random input via stdin. This might be far less effective when trying to fuzz a library that performs a complicated function, such as parsing a graphics image. A harness is a sequence of inputs, a valid file, a series of instructions, as concise as possible that provides an entry point into the program, typically uses it in a very simple way, and provides access to a place where it is possible to execute a decent amount of code that you want to fuzz. A mutational-based fuzzer can then use this harness as a starting point to generate random input, making changes to the input sequence to reach different areas of the code
Generally, creating a harness automatically for an arbitrary program is non-trivial task.
GUI Fuzzing on Windows
GUI applications are inherently complex due to their event-driven nature. User actions such as clicks, drags, and keyboard inputs trigger events that the application must handle. This complexity is compounded in Windows applications, which often integrate deeply with the operating system’s GUI components and APIs. Fuzzing these applications requires not just sending data inputs but simulating a wide range of user interactions in a manner that’s both meaningful and capable of uncovering bugs.
To solve these problems, we need some form of conversion between GUI to CLI to avoid overhead in generating graphics. For this we could write a specific harness that would allow us to invoke same function in the target program without interacting with the GUI. For example, if we want to write a harness for a PDF reader we would need to first find out which module is responsible for parsing the PDF file and then we would need to find out how to call this specific parsing function from our harness.
In addition, other issues exist that are specific to Windows and modern fuzzers:
- AFL does not support Windows binaries
- WinAFL exists, but is far more limited such as having no fork server mode. In practice, this means it will operate 10X-100X slower then native AFL
- Honggfuzz on Windows exists but has no feedback-based fuzzing support
- Another popular Windows fuzzer is Peach, but this also has no feedback based fuzzing
Issues in Harnessing
Harness generation is a very difficult task for many reasons:
- Need to decide precisely what the fuzz – avoiding the GUI code and only triggering actions.
- Since these actions are often not context free, you must know what call sequences are capable to activate this code properly. Blind function calls often will simply crash the program.
- Recovering proper input: for example, how to create a pointer to a structure that is needed to call a particular target function properly.
- Reconstructing control flow and dataflow dependencies
How to approach Harnessing
To determine the optimum fuzzing targets within a program, you can perform dynamic program analysis. This is nothing more than executing a program multiple times while logging program traces and capturing promising functions. These are determined by two basic guidelines:
- Do they accept file paths as input?
- Does it actually perform a system call to open the file and then parse the contents of that file?
The program then analyzes the call graph to find the deepest or earliest functions that meet these requirements. By running the program multiple times on the same input, you can abuse ASLR to determine which variables are pointers since they always change in values, representing different memory addresses, while always pointing to the same data. We then build a harness skeleton by reconstructing all the function prototypes, combining static analysis plus traces from earlier dynamic analysis. Is also important to avoid irrelevant calls with multithreaded programs – often only one thread does things interesting while the other threads do nothing or perform irrelevant behavior. It is possible to do this by using logged thread IDs to make sure we only analyze one thread at a time.
The final challenge is to identify control flow & data flow dependencies. To resolve control flow dependencies, static analysis is used. If functions are called in sequence, then implement that same sequence in the harness.
Finally test performance of each harness and make sure code coverage increases.
Summary
So in this blog, we’ve learned the fundamentals of fuzzing – a technique where you bombard software with random inputs to reveal hidden bugs. We’ve explored different types of fuzzers, from the basic “dumb” fuzzers that rely on randomness to the more advanced coverage-guided fuzzers that intelligently adapt based on how much of the code they’ve explored. The importance of code coverage was emphasized, showing how it guides efficient fuzzing. We also discussed the concept of a corpus, the collection of initial test cases that influence the success of your fuzzing efforts. Finally, we touched on the complexities of harnessing, the process of creating focused test cases for complex software (like those with graphical user interfaces), particularly on Windows systems.
You can take this knowledge further by trying out different fuzzing tools like AFL or Peach to see what fits your testing needs best.